In computing, a rose tree is a term for the value of a tree data structure with a variable and unbounded number of branches per node.[1] The term is mostly used in the functional programming community, e.g., in the context of the Bird–Meertens formalism.[2] Apart from the multi-branching property, the most essential characteristic of rose trees is the coincidence of bisimilarity with identity: two distinct rose trees are never bisimilar.
Naming
The name "rose tree" was coined by Lambert Meertens to evoke the similarly named, and similarly structured, common rhododendron.[3]
We shall call such trees rose trees, a literal translation of rhododendron (Greek ῥόδον = rose, δένδρον = tree), because of resemblance to the habitus of this shrub, except that the latter does not grow upside-down on the Northern hemisphere.
Recursive definition
Well-founded rose trees can be defined by a recursive construction of entities of the following types:
- A base entity is an element of a predefined ground set V of values (the "tip"-values[3]).
-
A branching entity (alternatively, a forking entity or a forest entity) is either of the following sub-types:
- A set of entities.
- A sequence of entities.
- A partial map from a predefined set Σ of names to entities.
Any of (a)(b)(c) can be empty. Note that (b) can be seen as a special case of (c) – a sequence is just a map from an initial segment of the set of natural numbers.
- A pairing entity is an ordered pair (F, x) such that F is a branching entity and x is an element of a predefined set L of "label" values. Since a pairing entity can only contain a branching entity as its component, there is an induced division into sub-types (3a), (3b) or (3c) corresponding to sub-types of branching entities.

Typically, only some combinations of entity types are used for the construction. The original paper[3] only considers 1+2b ("sequence-forking" rose trees) and 1+2a ("set-forking" rose trees). In later literature, the 1+2b variant is usually introduced by the following definition:
data Tree a = Leaf a | Node [Tree a]
A rose tree [...] is either a
leaf containing a value, or a node that can have an arbitrary list of subtrees
.[4]
The most common definition used in functional programming (particularly in Haskell) combines 3+2b:
data Rose α = Node α [Rose α]
An element of Rose α consists of a labelled node together with a list of subtrees
.[1]
That is, a rose tree is a pairing entity (type 3) whose branching entity is a sequence (thus of type 2b) of rose trees.
Sometimes even the combination 1+3b is considered.[5][6] The following table provides a summary of the most established combinations of entities.
Terminology Entities used Well-founded set (2a) Well-founded nested list value (2b)(1) Well-founded nested dictionary value (2c)(1) Well-founded nested data value (2b)(2c)(1) An L-name as known from forcing (2a)(3)[w 1] Well-founded rose tree in the most common sense (3)(2b)[w 1]
Notes:
- 1 2 For the (2a)(3) and (3)(2b) combinations, the second stated entity type is only intermediate - it is just used for the definition of the "final" entity which is of the first type stated. Moreover, the types are strictly alternating, i.e. a branching entity can only contain a pairing entity as its member.
General definition
General rose trees can be defined via bisimilarity of accessible pointed multidigraphs with appropriate labelling of nodes and arrows. These structures are generalization of the notion of accessible pointed graph (abbreviated as apg) from non-well-founded set theory. We will use the apq acronym for the below described multidigraph structures. This is meant as an abbreviation of "accessible pointed quiver" where quiver is an established synonym for "multidigraph".
In a correspondence to the types of entities used in the recursive definition, each node of an apq is assigned a type (1), (2a), (2b), (2c) or (3). The apqs are subject to conditions that mimic the properties of recursively constructed entities.
-
- A node of type (1) is an element of the predefined set V of ground values.
- A node of type (1) does not appear as the source of an arrow.
-
- A node of type (3) appears as the source of exactly one arrow.
- The target of the arrow mentioned in (a) is a node of type (2).
- Two distinct arrows with the same source node of type (2a) have distinct targets.
- A node is labelled iff it is of type (3). The label belongs to the predefined set L.
-
- An arrow is labelled by an index from if its source node is of type (2b).
- An arrow is labelled by a name from a predefined set Σ if its source node is of type (2c).
- Otherwise an arrow is unlabelled.
- Labels of arrows with the same source node are distinct.
- Labels of arrows with the same source node of type (2b) form an initial segment of .
A bisimilarity between apqs 𝒳 = (X, ...) and 𝒴 = (Y, ...) is a relation R ⊆ X × Y between nodes such that the roots of 𝒳 and 𝒴 are R-related and for every pair (x,y) of R-related nodes, the following are satisfied:
- The nodes x and y have the same type.
- If x and y are of type (1) then they are identical.
- If x and y are of type (3) then they have the same label.
-
For every arrow a of 𝒳 whose source node is x there exists an arrow b of 𝒴 whose source is y and
- the target nodes of a and b are R-related,
- the labels of a and b, if defined, are identical.
A symmetric condition is satisfied with 𝒳 and 𝒴 interchanged.
Two apqs 𝒳 and 𝒴 are said to be bisimilar if there exists a bisimilarity relation R for them. This establishes an equivalence relation on the class of all apqs.
A rose tree is then some fixed representation of the class 𝒞 of apqs that are bisimilar to some given apq 𝒳. If the root node of 𝒳 is of type (1) then 𝒞 = {𝒳}, thus 𝒞 can be represented by this root node. Otherwise, 𝒞 is a proper class – in this case the representation can be provided by Scott's trick to be the set of those elements of 𝒞 that have the lowest rank.
As a result of the above set-theoretic construction, the class ℛ of all rose trees is defined, depending on the sets V (ground values), Σ (arrow names) and L (node labels) as the definitory constituents. Subsequently, the structure of apqs can be carried over to a labelled multidigraph structure over ℛ. That is, elements of ℛ can themselves be considered as "nodes" with induced type assignment, node labelling and arrows. The class 𝒜 of arrows is a subclass of (ℛ × ℛ) ∪ (ℛ × ( ∪ Σ) × ℛ), that is, arrows are either source-target couples or source-label-target triples according to the type of the source.
For every element r of ℛ there is an induced apq 𝒳 = (X, A, r, ...) such that r is the root node of 𝒳 and the respective sets X and A of nodes and arrows of 𝒳 are formed by those elements of ℛ and 𝒜 that are accessible via a path of arrows starting at r. The induced apq 𝒳 is bisimilar to apqs used for the construction of r.
Pathname maps
Rose trees that do not contain set-branching nodes (type 2a) can be represented by pathname maps. A pathname is just a finite sequence of arrow labels. For an arrow path a→ = [a1, ..., an] (a finite sequence of consecutive arrows), the pathname of p is the corresponding sequence σ(a→) = [σ(a1), ..., σ(an)] of arrow labels. Here it is assumed that each arrow is labelled (σ denotes the labelling function). In general, each arrow path needs to be first reduced by removing all its arrows sourced at pairing nodes (type 3).
A pathname p is resolvable iff there exists a root-originating arrow path a→ whose pathname is p. Such a→ is uniquely given up to a possible unlabelled last arrow (sourced at a pairing node). The target node of a non-empty resolvable path is the target node of the last arrow of the correspondent root-originating arrow path that does not end with an unlabelled arrow. The target of the empty path is the root node.
Given a rose tree r that does not contain set-branching nodes, the pathname map of r is a map t that assigns each resolvable pathname p its value t(p) according to the following general scheme:
( ∪ Σ)⁎ ⊇ dom(t) (V ∪ {⊥} ∪ L) × T
Recall that ∪ Σ is the set of arrow labels ( is the set of natural numbers and Σ is the set of arrow names) L is the set of node labels, and V is the set of ground values. The additional symbols ⊥ and T respectively mean an indicator of a resolvable pathname and the set of type tags, T = {'1', '2b', '2c', '3b', '3c'}. The t map is defined by the following prescription (x denotes the target of p):
t(p) = (x, '1') if x is of type (1), (⊥, '2b') or (⊥, '2c') if x is of respective type (2b) or (2c), (ℓ, '3b') or (ℓ, '3c') if x is of respective type (3b) or (3c) and ℓ ∈ L is the label of x.
It can be shown that different rose trees have different pathname maps. For "homogeneous" rose trees there is no need for type tagging, and their pathname map t can be defined as summarized below:
In each case, there is a simple axiomatization in terms of pathnames:
- dom(t) is a non-empty prefix-closed subset of ⁎ or Σ⁎. In case of ⁎, dom(t) also needs to be "left-sibling-closed" to form a tree domain, see Encoding by sequences.
- In case of a nested list or a nested dictionary value, if p is a pathname that is non-maximal in dom(t), then t(p) = ⊥.[p 2]
In particular, a rose tree in the most common "Haskell" sense is just a map from a non-empty prefix-closed and left-sibling-closed set of finite sequences of natural numbers to a set L. Such a definition is mostly used outside the branch of functional programming, see Tree (automata theory). Typically, documents that use this definition do not mention the term "rose tree" at all.
Notes:
- 1 2 If dom(t) = M⁎ for a subset of or Σ then the pathname map t is a mapping of sequences of input symbols to output symbols of a Moore machine. Specifically, every Moore machine with the set M of input symbols being an initial segment of and with all states reachable is bisimilar to a rose tree in the Haskell sense, see the example of a non-well-founded rose tree. Similar relationship can be observed between nested dictionaries (or lists) and Mealy machines, see Nested dictionary.
- ↑
To ensure that a nested list or a nested dictionary is respectively a list or dictionary in the first place, the condition t(p) = ⊥ must be explicitly required to hold for the empty pathname p. This asserts that cases like
x = 5are not considered to be "tree values".
Examples
The diagrams below show two examples of rose trees together with the correspondent Haskell code. In both cases, the Data.Tree module[11] is used as it is provided by the Haskell containers package.[12] The module introduces rose trees as pairing entities by the following definition:
data Tree a = Node {
rootLabel :: a, -- ^ label value
subForest :: [Tree a] -- ^ zero or more child trees
}
Both examples are contrived so as to demonstrate the concept of "sharing of substructures"[13] which is a distinguished feature of rose trees.
In both cases, the labelling function is injective
(so that the labels 'a', 'b', 'c' or 'd' uniquely identify a subtree / node) which does not need to be satisfied in general.
The natural numbers (0,1,2 or 3) along the arrows indicate the zero-based position in which a tree appears in the subForest sequence of a particular "super-tree".
As a consequence of possible repetitions in subForest, there can be multiple arrows between nodes.
In each of the examples, the rose tree in question is labelled by 'a' and equals the value of the a variable in the code. In both diagrams, the tree is pointed to by a source-less arrow.
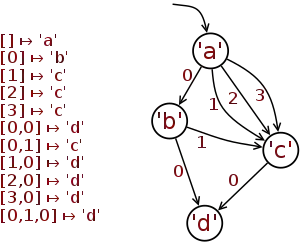
import Data.Tree
main :: IO ()
main = do
let d = Node { rootLabel = 'd', subForest = [] }
let c = Node { rootLabel = 'c', subForest = [d] }
let b = Node { rootLabel = 'b', subForest = [d,c] }
let a = Node { rootLabel = 'a', subForest = [b,c,c,c] }
print a
import Data.Tree
main :: IO ()
main = do
let root x = case x of
'a' -> (x,[x,'b'])
'b' -> (x,[x,'c'])
'c' -> (x,[x,'a'])
let a = unfoldTree root 'a'
putStrLn (take 900 (show a)
++ " ... (and so on)")
The first example presents a well-founded rose tree a obtained by an incremental construction. First d is constructed, then c then b and finally a. The rose tree can be represented by the pathname map shown on the left.
The second example presents a non-well-founded rose tree a built by a breadth-first constructor unfoldTree. The rose tree is a Moore machine, see notes above. Its pathname map
t : {0,1}⁎ → {'a','b','c'}
is defined by t(p) be respectively equal to 'a' or 'b' or 'c' according to n mod 3 where n is the number of occurrences of 1 in p.
Relation to tree data structures
The general definition provides a connection to tree data structures:
- Rose trees are tree structures modulo bisimilarity.
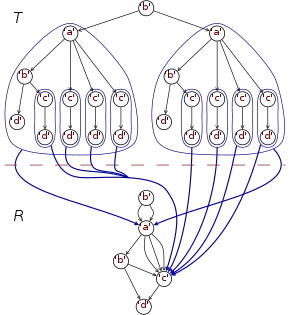
The "tree structures" are those apqs (labelled multidigraphs from the general definition) in which each node is accessible by a unique arrow path. Every rose tree is bisimilar to such a tree structure (since every apq is bisimilar to its unfolding) and every such tree structure is bisimilar to exactly one rose tree which can therefore be regarded as the value of the tree structure.
The diagram on the right shows an example of such a structure-to-value mapping. In the upper part of the diagram, a node-labelled ordered tree T is displayed, containing 23 nodes. In the lower part, a rose tree R is shown that is the value of T. (In both T and R, sibling arrows are implicitly ordered from left to right.) There is an induced subtree-to-subvalue mapping which is partially displayed by blue arrows.
Observe that the mapping is many-to-one: distinct tree data structures can have the same value. As a particular consequence, a rose tree in general is not a tree in terms of "subvalue" relationship between its subvalues, see #Terminological_controversy.
Tree data type
The value mapping described above can be used to clarify the difference between the terms "tree data structure" and "tree data type":
- A tree data type is a set of values of tree data structures.[dt 1]
Note that there are 2 degrees of discrepancy between the terms. This becomes apparent when one compares a single tree data type with a single tree data structure. A single tree data type contains (infinitely) many values each of which is represented by (infinitely) many tree data structures.
For example, given a set L = {'a','b','c','d'} of labels, the set of rose trees in the Haskell sense (3b) with labels taken from L is a single tree data type. All the above examples of rose trees belong to this data type.
Notes:
- ↑ However, not every set of values of tree data structures is a tree data type.
Terminological controversy
As it can be observed in the above text and diagrams, the term "rose tree" is controversial. There are two interrelated issues:
- Obscure meaning of "node".
- Discrepancy between "tree" and "sharing of substructures".
Interestingly, the term "node" does not appear in the original paper[3] except for a single occurrence of "nodes" in an informal paragraph on page 20. In later literature the word is used abundantly. This can already be observed in the quoted comments to the definitions:
A rose tree [...] is either a leaf [...] or a node [...]
.[4]An element of Rose α consists of a labelled node [...]
.[1]
In particular, the definition of rose trees in the most common Haskell sense suggests that (within the context of discourse) "node" and "tree" are synonyms. Does it mean that every rose tree is coincident with its root node? If so, is such a property considered specific to rose trees or does it also apply to other trees? Such questions are left unanswered.
The (B) problem becomes apparent when looking at the diagrams of the above examples. Both diagrams are faithful in the sense that each node is drawn exactly once. One can immediately see that the underlying graphs are not trees. Using a quotation from Tree (graph theory)
The various kinds of data structures referred to as trees in computer science have underlying graphs that are trees in graph theory [...]
one can conclude that rose trees in general are not trees in usual meaning known from computer science.
Bayesian rose tree
There is at least one adoption of the term "rose tree" in computer science in which "sharing of substructures" is precluded. The concept of a Bayesian rose tree is based on the following definition of rose trees:
T is a rose tree if either T = {x} for some data point x or T = {T1, ... ,TnT} where Ti's are rose trees over disjoint sets of data points.[14]
References
- 1 2 3 Bird, Richard (1998). Introduction to Functional Programming using Haskell. Hemel Hempstead, Hertfordshire, UK: Prentice Hall Europe. p. 195. ISBN 0-13-484346-0.
- ↑ Malcolm, Grant (1990). "Data structures and program transformation". Science of Computer Programming. 14 (2): 255–279. doi:10.1016/0167-6423(90)90023-7.
- 1 2 3 4 Meertens, Lambert (January 1988). "First steps towards the Theory of Rose Trees" (PDF).
{{cite journal}}: Cite journal requires|journal=(help) - 1 2 Bird, Richard; Gibbons, Jeremy (2020). Algorithm Design with Haskell. Cambridge University Press. ISBN 9781108491617.
- ↑ Skillicorn, David B. (1996). "Parallel implementation of tree skeletons" (PDF). Journal of Parallel and Distributed Computing. 39 (2): 115–125. doi:10.1006/jpdc.1996.0160.
- ↑ Seemann, Mark. "Church-encoded rose tree".
- ↑ Morawietz, Frank (2008). Two-Step Approaches to Natural Language Formalism. Walter de Gruyter. ISBN 9783110197259.
- ↑ Kosky, Anthony (1995). Transforming Databases with Recursive Data Structures (Thesis).
- ↑ Niwiński, Damian (1997). "Fixed point characterization of infinite behavior of finite-state systems" (PDF). Theoretical Computer Science. 189 (1–2): 1–69. doi:10.1016/S0304-3975(97)00039-X.
- ↑ Dagnino, Francesco (2020). "Coaxioms: flexible coinductive definitions by inference systems". Logical Methods in Computer Science. 15. arXiv:1808.02943. doi:10.23638/LMCS-15(1:26)2019. S2CID 51955443.
- ↑ "Data.Tree".
- ↑ "containers: Assorted concrete container types".
- ↑ Gibbons, Jeremy (1991). Algebras for Tree Algorithms (PDF) (Ph.D.). Oxford University.
- ↑ Blundell, Charles; Whye Teh, Yee; Heller, Katherine A. (2010). Bayesian rose trees (PDF). 26th Conference on Uncertainty in Artificial Intelligence.