| Part of a series on |
| Machine learning and data mining |
|---|
Deep reinforcement learning (deep RL) is a subfield of machine learning that combines reinforcement learning (RL) and deep learning. RL considers the problem of a computational agent learning to make decisions by trial and error. Deep RL incorporates deep learning into the solution, allowing agents to make decisions from unstructured input data without manual engineering of the state space. Deep RL algorithms are able to take in very large inputs (e.g. every pixel rendered to the screen in a video game) and decide what actions to perform to optimize an objective (e.g. maximizing the game score). Deep reinforcement learning has been used for a diverse set of applications including but not limited to robotics, video games, natural language processing, computer vision, education, transportation, finance and healthcare.[1]
Overview
Deep learning

Deep learning is a form of machine learning that utilizes a neural network to transform a set of inputs into a set of outputs via an artificial neural network. Deep learning methods, often using supervised learning with labeled datasets, have been shown to solve tasks that involve handling complex, high-dimensional raw input data such as images, with less manual feature engineering than prior methods, enabling significant progress in several fields including computer vision and natural language processing. In the past decade, deep RL has achieved remarkable results on a range of problems, from single and multiplayer games such as GO, Atari Games, and Dota 2, to robotics[2]
Reinforcement learning
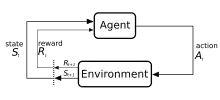
Reinforcement learning is a process in which an agent learns to make decisions through trial and error. This problem is often modeled mathematically as a Markov decision process (MDP), where an agent at every timestep is in a state , takes action , receives a scalar reward and transitions to the next state according to environment dynamics . The agent attempts to learn a policy , or map from observations to actions, in order to maximize its returns (expected sum of rewards). In reinforcement learning (as opposed to optimal control) the algorithm only has access to the dynamics through sampling.





Deep reinforcement learning
In many practical decision-making problems, the states of the MDP are high-dimensional (e.g., images from a camera or the raw sensor stream from a robot) and cannot be solved by traditional RL algorithms. Deep reinforcement learning algorithms incorporate deep learning to solve such MDPs, often representing the policy or other learned functions as a neural network and developing specialized algorithms that perform well in this setting.
History
Along with rising interest in neural networks beginning in the mid 1980s, interest grew in deep reinforcement learning, where a neural network is used in reinforcement learning to represent policies or value functions. Because in such a system, the entire decision making process from sensors to motors in a robot or agent involves a single neural network, it is also sometimes called end-to-end reinforcement learning.[3] One of the first successful applications of reinforcement learning with neural networks was TD-Gammon, a computer program developed in 1992 for playing backgammon.[4] Four inputs were used for the number of pieces of a given color at a given location on the board, totaling 198 input signals. With zero knowledge built in, the network learned to play the game at an intermediate level by self-play and TD().

Seminal textbooks by Sutton and Barto on reinforcement learning,[5] Bertsekas and Tsitiklis on neuro-dynamic programming,[6] and others[7] advanced knowledge and interest in the field.
Katsunari Shibata's group showed that various functions emerge in this framework,[8][9][10] including image recognition, color constancy, sensor motion (active recognition), hand-eye coordination and hand reaching movement, explanation of brain activities, knowledge transfer, memory,[11] selective attention, prediction, and exploration.[9][12]
Starting around 2012, the so called Deep learning revolution led to an increased interest in using deep neural networks as function approximators across a variety of domains. This led to a renewed interest in researchers using deep neural networks to learn the policy, value, and/or Q functions present in existing reinforcement learning algorithms.
Beginning around 2013, DeepMind showed impressive learning results using deep RL to play Atari video games.[13][14] The computer player a neural network trained using a deep RL algorithm, a deep version of Q-learning they termed deep Q-networks (DQN), with the game score as the reward. They used a deep convolutional neural network to process 4 frames RGB pixels (84x84) as inputs. All 49 games were learned using the same network architecture and with minimal prior knowledge, outperforming competing methods on almost all the games and performing at a level comparable or superior to a professional human game tester.[14]
Deep reinforcement learning reached another milestone in 2015 when AlphaGo,[15] a computer program trained with deep RL to play Go, became the first computer Go program to beat a human professional Go player without handicap on a full-sized 19×19 board. In a subsequent project in 2017, AlphaZero improved performance on Go while also demonstrating they could use the same algorithm to learn to play chess and shogi at a level competitive or superior to existing computer programs for those games, and again improved in 2019 with MuZero.[16] Separately, another milestone was achieved by researchers from Carnegie Mellon University in 2019 developing Pluribus, a computer program to play poker that was the first to beat professionals at multiplayer games of no-limit Texas hold 'em. OpenAI Five, a program for playing five-on-five Dota 2 beat the previous world champions in a demonstration match in 2019.
Deep reinforcement learning has also been applied to many domains beyond games. In robotics, it has been used to let robots perform simple household tasks[17] and solve a Rubik's cube with a robot hand.[18][19] Deep RL has also found sustainability applications, used to reduce energy consumption at data centers.[20] Deep RL for autonomous driving is an active area of research in academia and industry.[21] Loon explored deep RL for autonomously navigating their high-altitude balloons.[22]
Algorithms
Various techniques exist to train policies to solve tasks with deep reinforcement learning algorithms, each having their own benefits. At the highest level, there is a distinction between model-based and model-free reinforcement learning, which refers to whether the algorithm attempts to learn a forward model of the environment dynamics.
In model-based deep reinforcement learning algorithms, a forward model of the environment dynamics is estimated, usually by supervised learning using a neural network. Then, actions are obtained by using model predictive control using the learned model. Since the true environment dynamics will usually diverge from the learned dynamics, the agent re-plans often when carrying out actions in the environment. The actions selected may be optimized using Monte Carlo methods such as the cross-entropy method, or a combination of model-learning with model-free methods.
In model-free deep reinforcement learning algorithms, a policy is learned without explicitly modeling the forward dynamics. A policy can be optimized to maximize returns by directly estimating the policy gradient[23] but suffers from high variance, making it impractical for use with function approximation in deep RL. Subsequent algorithms have been developed for more stable learning and widely applied.[24][25] Another class of model-free deep reinforcement learning algorithms rely on dynamic programming, inspired by temporal difference learning and Q-learning. In discrete action spaces, these algorithms usually learn a neural network Q-function that estimates the future returns taking action from state .[13] In continuous spaces, these algorithms often learn both a value estimate and a policy.[26][27][28]

Research
Deep reinforcement learning is an active area of research, with several lines of inquiry.
Exploration
An RL agent must balance the exploration/exploitation tradeoff: the problem of deciding whether to pursue actions that are already known to yield high rewards or explore other actions in order to discover higher rewards. RL agents usually collect data with some type of stochastic policy, such as a Boltzmann distribution in discrete action spaces or a Gaussian distribution in continuous action spaces, inducing basic exploration behavior. The idea behind novelty-based, or curiosity-driven, exploration is giving the agent a motive to explore unknown outcomes in order to find the best solutions. This is done by "modify[ing] the loss function (or even the network architecture) by adding terms to incentivize exploration".[29] An agent may also be aided in exploration by utilizing demonstrations of successful trajectories, or reward-shaping, giving an agent intermediate rewards that are customized to fit the task it is attempting to complete.[30]
Off-policy reinforcement learning
An important distinction in RL is the difference between on-policy algorithms that require evaluating or improving the policy that collects data, and off-policy algorithms that can learn a policy from data generated by an arbitrary policy. Generally, value-function based methods such as Q-learning are better suited for off-policy learning and have better sample-efficiency - the amount of data required to learn a task is reduced because data is re-used for learning. At the extreme, offline (or "batch") RL considers learning a policy from a fixed dataset without additional interaction with the environment.
Inverse reinforcement learning
Inverse RL refers to inferring the reward function of an agent given the agent's behavior. Inverse reinforcement learning can be used for learning from demonstrations (or apprenticeship learning) by inferring the demonstrator's reward and then optimizing a policy to maximize returns with RL. Deep learning approaches have been used for various forms of imitation learning and inverse RL.[31]
Goal-conditioned reinforcement learning
Another active area of research is in learning goal-conditioned policies, also called contextual or universal policies that take in an additional goal as input to communicate a desired aim to the agent.[32] Hindsight experience replay is a method for goal-conditioned RL that involves storing and learning from previous failed attempts to complete a task.[33] While a failed attempt may not have reached the intended goal, it can serve as a lesson for how achieve the unintended result through hindsight relabeling.


Multi-agent reinforcement learning
Many applications of reinforcement learning do not involve just a single agent, but rather a collection of agents that learn together and co-adapt. These agents may be competitive, as in many games, or cooperative as in many real-world multi-agent systems. Multi-agent reinforcement learning studies the problems introduced in this setting.
Generalization
The promise of using deep learning tools in reinforcement learning is generalization: the ability to operate correctly on previously unseen inputs. For instance, neural networks trained for image recognition can recognize that a picture contains a bird even it has never seen that particular image or even that particular bird. Since deep RL allows raw data (e.g. pixels) as input, there is a reduced need to predefine the environment, allowing the model to be generalized to multiple applications. With this layer of abstraction, deep reinforcement learning algorithms can be designed in a way that allows them to be general and the same model can be used for different tasks.[34] One method of increasing the ability of policies trained with deep RL policies to generalize is to incorporate representation learning.
References
- ↑ Francois-Lavet, Vincent; Henderson, Peter; Islam, Riashat; Bellemare, Marc G.; Pineau, Joelle (2018). "An Introduction to Deep Reinforcement Learning". Foundations and Trends in Machine Learning. 11 (3–4): 219–354. arXiv:1811.12560. Bibcode:2018arXiv181112560F. doi:10.1561/2200000071. ISSN 1935-8237. S2CID 54434537.
- ↑ Graesser, Laura. "Foundations of Deep Reinforcement Learning: Theory and Practice in Python". Open Library Telkom University. Retrieved 2023-07-01.
- ↑ Demis, Hassabis (March 11, 2016). Artificial Intelligence and the Future (Speech).
- ↑ Tesauro, Gerald (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM. 38 (3): 58–68. doi:10.1145/203330.203343. S2CID 8763243. Archived from the original on 2010-02-09. Retrieved 2017-03-10.
- ↑ Sutton, Richard; Barto, Andrew (September 1996). Reinforcement Learning: An Introduction. Athena Scientific.
- ↑ Bertsekas, John; Tsitsiklis, Dimitri (September 1996). Neuro-Dynamic Programming. Athena Scientific. ISBN 1-886529-10-8.
- ↑ Miller, W. Thomas; Werbos, Paul; Sutton, Richard (1990). Neural Networks for Control.
- ↑ Shibata, Katsunari; Okabe, Yoichi (1997). Reinforcement Learning When Visual Sensory Signals are Directly Given as Inputs (PDF). International Conference on Neural Networks (ICNN) 1997. Archived from the original (PDF) on 2020-12-09. Retrieved 2020-12-01.
- 1 2 Shibata, Katsunari; Iida, Masaru (2003). Acquisition of Box Pushing by Direct-Vision-Based Reinforcement Learning (PDF). SICE Annual Conference 2003. Archived from the original (PDF) on 2020-12-09. Retrieved 2020-12-01.
- ↑ Shibata, Katsunari (March 7, 2017). "Functions that Emerge through End-to-End Reinforcement Learning". arXiv:1703.02239 [cs.AI].
- ↑ Utsunomiya, Hiroki; Shibata, Katsunari (2008). Contextual Behavior and Internal Representations Acquired by Reinforcement Learning with a Recurrent Neural Network in a Continuous State and Action Space Task (PDF). International Conference on Neural Information Processing (ICONIP) '08. Archived from the original (PDF) on 2017-08-10. Retrieved 2020-12-14.
- ↑ Shibata, Katsunari; Kawano, Tomohiko (2008). Learning of Action Generation from Raw Camera Images in a Real-World-like Environment by Simple Coupling of Reinforcement Learning and a Neural Network (PDF). International Conference on Neural Information Processing (ICONIP) '08. Archived from the original (PDF) on 2020-12-11. Retrieved 2020-12-01.
- 1 2 Mnih, Volodymyr; et al. (December 2013). Playing Atari with Deep Reinforcement Learning (PDF). NIPS Deep Learning Workshop 2013.
- 1 2 Mnih, Volodymyr; et al. (2015). "Human-level control through deep reinforcement learning". Nature. 518 (7540): 529–533. Bibcode:2015Natur.518..529M. doi:10.1038/nature14236. PMID 25719670. S2CID 205242740.
- ↑ Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; Driessche, George van den; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda; Lanctot, Marc; Dieleman, Sander; Grewe, Dominik; Nham, John; Kalchbrenner, Nal; Sutskever, Ilya; Lillicrap, Timothy; Leach, Madeleine; Kavukcuoglu, Koray; Graepel, Thore; Hassabis, Demis (28 January 2016). "Mastering the game of Go with deep neural networks and tree search". Nature. 529 (7587): 484–489. Bibcode:2016Natur.529..484S. doi:10.1038/nature16961. ISSN 0028-0836. PMID 26819042. S2CID 515925.

- ↑ Schrittwieser, Julian; Antonoglou, Ioannis; Hubert, Thomas; Simonyan, Karen; Sifre, Laurent; Schmitt, Simon; Guez, Arthur; Lockhart, Edward; Hassabis, Demis; Graepel, Thore; Lillicrap, Timothy; Silver, David (23 December 2020). "Mastering Atari, Go, chess and shogi by planning with a learned model". Nature. 588 (7839): 604–609. arXiv:1911.08265. Bibcode:2020Natur.588..604S. doi:10.1038/s41586-020-03051-4. PMID 33361790. S2CID 208158225.
- ↑ Levine, Sergey; Finn, Chelsea; Darrell, Trevor; Abbeel, Pieter (January 2016). "End-to-end training of deep visuomotor policies" (PDF). JMLR. 17. arXiv:1504.00702.
- ↑ "OpenAI - Solving Rubik's Cube With A Robot Hand". OpenAI.
- ↑ OpenAI; et al. (2019). Solving Rubik's Cube with a Robot Hand. arXiv:1910.07113.
- ↑ "DeepMind AI Reduces Google Data Centre Cooling Bill by 40%". DeepMind.
- ↑ "Machine Learning for Autonomous Driving Workshop @ NeurIPS 2021". NeurIPS 2021. December 2021.
- ↑ Bellemare, Marc; Candido, Salvatore; Castro, Pablo; Gong, Jun; Machado, Marlos; Moitra, Subhodeep; Ponda, Sameera; Wang, Ziyu (2 December 2020). "Autonomous navigation of stratospheric balloons using reinforcement learning". Nature. 588 (7836): 77–82. Bibcode:2020Natur.588...77B. doi:10.1038/s41586-020-2939-8. PMID 33268863. S2CID 227260253.
- ↑ Williams, Ronald J (1992). "Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning". Machine Learning. 8 (3–4): 229–256. doi:10.1007/BF00992696. S2CID 2332513.
- ↑ Schulman, John; Levine, Sergey; Moritz, Philipp; Jordan, Michael; Abbeel, Pieter (2015). Trust Region Policy Optimization. International Conference on Machine Learning (ICML). arXiv:1502.05477.
- ↑ Schulman, John; Wolski, Filip; Dhariwal, Prafulla; Radford, Alec; Klimov, Oleg (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- ↑ Lillicrap, Timothy; Hunt, Jonathan; Pritzel, Alexander; Heess, Nicolas; Erez, Tom; Tassa, Yuval; Silver, David; Wierstra, Daan (2016). Continuous control with deep reinforcement learning. International Conference on Learning Representations (ICLR). arXiv:1509.02971.
- ↑ Mnih, Volodymyr; Puigdomenech Badia, Adria; Mirzi, Mehdi; Graves, Alex; Harley, Tim; Lillicrap, Timothy; Silver, David; Kavukcuoglu, Koray (2016). Asynchronous Methods for Deep Reinforcement Learning. International Conference on Machine Learning (ICML). arXiv:1602.01783.
- ↑ Haarnoja, Tuomas; Zhou, Aurick; Levine, Sergey; Abbeel, Pieter (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. International Conference on Machine Learning (ICML). arXiv:1801.01290.
- ↑ Reizinger, Patrik; Szemenyei, Márton (2019-10-23). "Attention-Based Curiosity-Driven Exploration in Deep Reinforcement Learning". ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 3542–3546. arXiv:1910.10840. doi:10.1109/ICASSP40776.2020.9054546. ISBN 978-1-5090-6631-5. S2CID 204852215.
- ↑ Wiewiora, Eric (2010), "Reward Shaping", in Sammut, Claude; Webb, Geoffrey I. (eds.), Encyclopedia of Machine Learning, Boston, MA: Springer US, pp. 863–865, doi:10.1007/978-0-387-30164-8_731, ISBN 978-0-387-30164-8, retrieved 2020-11-16
- ↑ Wulfmeier, Markus; Ondruska, Peter; Posner, Ingmar (2015). "Maximum Entropy Deep Inverse Reinforcement Learning". arXiv:1507.04888 [cs.LG].
- ↑ Schaul, Tom; Horgan, Daniel; Gregor, Karol; Silver, David (2015). Universal Value Function Approximators. International Conference on Machine Learning (ICML).
- ↑ Andrychowicz, Marcin; Wolski, Filip; Ray, Alex; Schneider, Jonas; Fong, Rachel; Welinder, Peter; McGrew, Bob; Tobin, Josh; Abbeel, Pieter; Zaremba, Wojciech (2018). Hindsight Experience Replay. Advances in Neural Information Processing Systems (NeurIPS). arXiv:1707.01495.
- ↑ Packer, Charles; Gao, Katelyn; Kos, Jernej; Krähenbühl, Philipp; Koltun, Vladlen; Song, Dawn (2019-03-15). "Assessing Generalization in Deep Reinforcement Learning". arXiv:1810.12282 [cs.LG].