| Cray-1 | |
|---|---|
.jpg.webp) A Cray-1 on display at the Science Museum in London | |
| Design | |
| Manufacturer | Cray Research |
| Designer | Seymour Cray |
| Release date | 1975 |
| Units sold | Over 100 |
| Price | US$7.9 million in 1977 (equivalent to $38.2 million in 2022) |
| Casing | |
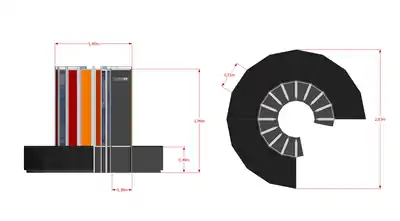
| Dimensions | Height: 196 cm (77 in)[1] Dia. (base): 263 cm (104 in)[1] Dia. (columns): 145 cm (57 in)[1] |
| Weight | 5.5 tons (Cray-1A) |
| Power | 115 kW @ 208 V 400 Hz[1] |
| System | |
| Front-end | Data General Eclipse |
| Operating system | COS & UNICOS |
| CPU | 64-bit processor @ 80 MHz[1] |
| Memory | 8.39 Megabytes (up to 1 048 576 words)[1] |
| Storage | 303 Megabytes (DD19 Unit)[1] |
| FLOPS | 160 MFLOPS |
| Successor | Cray X-MP |

The Cray-1 was a supercomputer designed, manufactured and marketed by Cray Research. Announced in 1975, the first Cray-1 system was installed at Los Alamos National Laboratory in 1976. Eventually, eighty Cray-1s were sold, making it one of the most successful supercomputers in history. It is perhaps best known for its unique shape, a relatively small C-shaped cabinet with a ring of benches around the outside covering the power supplies and the cooling system.
The Cray-1 was the first supercomputer to successfully implement the vector processor design. These systems improve the performance of math operations by arranging memory and registers to quickly perform a single operation on a large set of data. Previous systems like the CDC STAR-100 and ASC had implemented these concepts but did so in a way that seriously limited their performance. The Cray-1 addressed these problems and produced a machine that ran several times faster than any similar design.
The Cray-1's architect was Seymour Cray; the chief engineer was Cray Research co-founder Lester Davis.[2] They would go on to design several new machines using the same basic concepts, and retained the performance crown into the 1990s.
History
From 1968 to 1972, Seymour Cray of Control Data Corporation (CDC) worked on the CDC 8600, the successor to his earlier CDC 6600 and CDC 7600 designs. The 8600 was essentially made up of four 7600s in a box with an additional special mode that allowed them to operate lock-step in a SIMD fashion.
Jim Thornton, formerly Cray's engineering partner on earlier designs, had started a more radical project known as the CDC STAR-100. Unlike the 8600's brute-force approach to performance, the STAR took an entirely different route. The main processor of the STAR had lower performance than the 7600, but added hardware and instructions to speed up particularly common supercomputer tasks.
By 1972, the 8600 had reached a dead end; the machine was so incredibly complex that it was impossible to get one working properly. Even a single faulty component would render the machine non-operational. Cray went to William Norris, Control Data's CEO, saying that a redesign from scratch was needed. At the time, the company was in serious financial trouble, and with the STAR in the pipeline as well, Norris could not invest the money.
As a result, Cray left CDC and started Cray Research very close to the CDC lab. In the back yard of the land he purchased in Chippewa Falls, Cray and a group of former CDC employees started looking for ideas. At first, the concept of building another supercomputer seemed impossible, but after Cray Research's Chief Technology Officer travelled to Wall Street and found a lineup of investors willing to back Cray, all that was needed was a design.
For four years Cray Research designed its first computer.[3] In 1975 the 80 MHz Cray-1 was announced. The excitement was so high that a bidding war for the first machine broke out between Lawrence Livermore National Laboratory and Los Alamos National Laboratory, the latter eventually winning and receiving serial number 001 in 1976 for a six-month trial. The National Center for Atmospheric Research (NCAR) was the first official customer of Cray Research in 1977, paying US$8.86 million ($7.9 million plus $1 million for the disks) for serial number 3. The NCAR machine was decommissioned in 1989.[4] The company expected to sell perhaps a dozen of the machines, and set the selling price accordingly, but ultimately over 80 Cray-1s of all types were sold, priced from $5M to $8M. The machine made Seymour Cray a celebrity and his company a success, lasting until the supercomputer crash in the early 1990s.
Based on a recommendation by William Perry's study, the NSA purchased a Cray-1 for theoretical research in cryptanalysis. According to Budiansky, "Though standard histories of Cray Research would persist for decades in stating that the company's first customer was Los Alamos National Laboratory, in fact it was NSA..."[5]
The 160 MFLOPS Cray-1 was succeeded in 1982 by the 800 MFLOPS Cray X-MP, the first Cray multi-processing computer. In 1985, the very advanced Cray-2, capable of 1.9 GFLOPS peak performance, succeeded the first two models but met a somewhat limited commercial success because of certain problems at producing sustained performance in real-world applications. A more conservatively designed evolutionary successor of the Cray-1 and X-MP models was therefore made by the name Cray Y-MP and launched in 1988.
By comparison, the processor in a typical 2013 smart device, such as a Google Nexus 10 or HTC One, performs at roughly 1 GFLOPS,[6] while the A13 processor in a 2020 iPhone 11 performs at 154.9 GFLOPS,[7] a mark supercomputers succeeding the Cray-1 would not reach until 1994.
Background
Typical scientific workloads consist of reading in large data sets, transforming them in some way and then writing them back out again. Normally the transformations being applied are identical across all of the data points in the set. For instance, the program might add 5 to every number in a set of a million numbers.
In simple computers the program would loop over all million numbers, adding five, thereby executing a million instructions saying a = add b, c. Internally the computer solves this instruction in several steps. First it reads the instruction from memory and decodes it, then it collects any additional information it needs, in this case the numbers b and c, and then finally runs the operation and stores the results. The end result is that the computer requires tens or hundreds of millions of cycles to carry out these operations.
Vector machines
In the STAR, new instructions essentially wrote the loops for the user. The user told the machine where in memory the list of numbers was stored, then fed in a single instruction a(1..1000000) = addv b(1..1000000), c(1..1000000). At first glance it appears the savings are limited; in this case the machine fetches and decodes only a single instruction instead of 1,000,000, thereby saving 1,000,000 fetches and decodes, perhaps one-fourth of the overall time.
The real savings are not so obvious. Internally, the CPU of the computer is built up from a number of separate parts dedicated to a single task, for instance, adding a number, or fetching from memory. Normally, as the instruction flows through the machine, only one part is active at any given time. This means that each sequential step of the entire process must complete before a result can be saved. The addition of an instruction pipeline changes this. In such machines the CPU will "look ahead" and begin fetching succeeding instructions while the current instruction is still being processed. In this assembly line fashion any one instruction still requires as long to complete, but as soon as it finishes executing, the next instruction is right behind it, with most of the steps required for its execution already completed.
Vector processors use this technique with one additional trick. Because the data layout is in a known format — a set of numbers arranged sequentially in memory — the pipelines can be tuned to improve the performance of fetches. On the receipt of a vector instruction, special hardware sets up the memory access for the arrays and stuffs the data into the processor as fast as possible.
CDC's approach in the STAR used what is today known as a memory-memory architecture. This referred to the way the machine gathered data. It set up its pipeline to read from and write to memory directly. This allowed the STAR to use vectors of length not limited by the length of registers, making it highly flexible. Unfortunately, the pipeline had to be very long in order to allow it to have enough instructions in flight to make up for the slow memory. That meant the machine incurred a high cost when switching from processing vectors to performing operations on non-vector operands. Additionally, the low scalar performance of the machine meant that after the switch had taken place and the machine was running scalar instructions, the performance was quite poor. The result was rather disappointing real-world performance, something that could, perhaps, have been forecast by Amdahl's law.
Cray's approach
Cray studied the failure of the STAR and learned from it. He decided that in addition to fast vector processing, his design would also require excellent all-around scalar performance. That way when the machine switched modes, it would still provide superior performance. Additionally he noticed that the workloads could be dramatically improved in most cases through the use of registers.
Just as earlier machines had ignored the fact that most operations were being applied to many data points, the STAR ignored the fact that those same data points would be repeatedly operated on. Whereas the STAR would read and process the same memory five times to apply five vector operations on a set of data, it would be much faster to read the data into the CPU's registers once, and then apply the five operations. However, there were limitations with this approach. Registers were significantly more expensive in terms of circuitry, so only a limited number could be provided. This implied that Cray's design would have less flexibility in terms of vector sizes. Instead of reading any sized vector several times as in the STAR, the Cray-1 would have to read only a portion of the vector at a time, but it could then run several operations on that data prior to writing the results back to memory. Given typical workloads, Cray felt that the small cost incurred by being required to break large sequential memory accesses into segments was a cost well worth paying.
Since the typical vector operation would involve loading a small set of data into the vector registers and then running several operations on it, the vector system of the new design had its own separate pipeline. For instance, the multiplication and addition units were implemented as separate hardware, so the results of one could be internally pipelined into the next, the instruction decode having already been handled in the machine's main pipeline. Cray referred to this concept as chaining, as it allowed programmers to "chain together" several instructions and extract higher performance.
Description

The new machine was the first Cray design to use integrated circuits (ICs). Although ICs had been available since the 1960s, it was only in the early 1970s that they reached the performance necessary for high-speed applications. The Cray-1 used only four different IC types, an ECL dual 5-4 NOR gate (one 5-input, and one 4-input, each with differential output),[8] another slower MECL 10K 5-4 NOR gate used for address fanout, a 16×4-bit high speed (6 ns) static RAM (SRAM) used for registers and a 1,024×1-bit 48 ns SRAM used for the main memory. These integrated circuits were supplied by Fairchild Semiconductor and Motorola.[9] In all, the Cray-1 contained about 200,000 gates.
ICs were mounted on large five-layer printed circuit boards, with up to 144 ICs per board. Boards were then mounted back to back for cooling (see below) and placed in twenty-four 28-inch-high (710 mm) racks containing 72 double-boards. The typical module (distinct processing unit) required one or two boards. In all the machine contained 1,662 modules in 113 varieties.
Each cable between the modules was a twisted pair, cut to a specific length in order to guarantee the signals arrived at precisely the right time and minimize electrical reflection. Each signal produced by the ECL circuitry was a differential pair, so the signals were balanced. This tended to make the demand on the power supply more constant and reduce switching noise. The load on the power supply was so evenly balanced that Cray boasted that the power supply was unregulated. To the power supply, the entire computer system looked like a simple resistor.
The high-performance ECL circuitry generated considerable heat, and Cray's designers spent as much effort on the design of the refrigeration system as they did on the rest of the mechanical design. In this case, each circuit board was paired with a second, placed back to back with a sheet of copper between them. The copper sheet conducted heat to the edges of the cage, where liquid Freon running in stainless steel pipes drew it away to the cooling unit below the machine. The first Cray-1 was delayed six months due to problems in the cooling system; lubricant that is normally mixed with the Freon to keep the compressor running would leak through the seals and eventually coat the boards with oil until they shorted out. New welding techniques had to be used to properly seal the tubing.
In order to bring maximum speed out of the machine, the entire chassis was bent into a large C-shape. Speed-dependent portions of the system were placed on the "inside edge" of the chassis, where the wire-lengths were shorter. This allowed the cycle time to be decreased to 12.5 ns (80 MHz), not as fast as the 8 ns 8600 he had given up on, but fast enough to beat CDC 7600 and the STAR. NCAR estimated that the overall throughput on the system was 4.5 times that of the CDC 7600.[10]
The Cray-1 was built as a 64-bit system, a departure from the 7600/6600, which were 60-bit machines (a change was also planned for the 8600). Addressing was 24-bit, with a maximum of 1,048,576 64-bit words (1 megaword) of main memory, where each word also had eight parity bits for a total of 72 bits per word.[11] Memory was spread across 16 interleaved memory banks, each with a 50 ns cycle time, allowing up to four words to be read per cycle. Smaller configurations could have 0.25 or 0.5 megawords of main memory. Maximum aggregate memory bandwidth was 638 Mbit/s.[11]
The main register set consisted of eight 64-bit scalar (S) registers and eight 24-bit address (A) registers. These were backed by a set of sixty-four registers each for S and A temporary storage known as T and B respectively, which could not be seen by the functional units. The vector system added another eight 64-element by 64-bit vector (V) registers, as well as a vector length (VL) and vector mask (VM). Finally, the system also included a 64-bit real-time clock register and four 64-bit instruction buffers that held sixty-four 16-bit instructions each. The hardware was set up to allow the vector registers to be fed at one word per cycle, while the address and scalar registers required two cycles. In contrast, the entire 16-word instruction buffer could be filled in four cycles.
The Cray-1 had twelve pipelined functional units. The 24-bit address arithmetic was performed in an add unit and a multiply unit. The scalar portion of the system consisted of an add unit, a logical unit, a population count, a leading zero count unit and a shift unit. The vector portion consisted of add, logical and shift units. The floating point functional units were shared between the scalar and vector portions, and these consisted of add, multiply and reciprocal approximation units.
The system had limited parallelism. It could issue one instruction per clock cycle, for a theoretical performance of 80 MIPS, but with vector floating-point multiplication and addition occurring in parallel theoretical performance was 160[12] MFLOPS. (The reciprocal approximation unit could also operate in parallel, but did not deliver a true floating-point result - two additional multiplications were needed to achieve a full division.)
Since the machine was designed to operate on large data sets, the design also dedicated considerable circuitry to I/O. Earlier Cray designs at CDC had included separate computers dedicated to this task, but this was no longer needed. Instead the Cray-1 included four six-channel controllers, each of which was given access to main memory once every four cycles. The channels were 16 bits wide and included three control bits and four bits for error correction, so the maximum transfer speed was one word per 100 ns, or 500 thousand words per second for the entire machine.
The initial model, the Cray-1A, weighed 10,500 pounds (4,800 kg) including the Freon refrigeration system. Configured with 1 million words of main memory, the machine and its power supplies consumed about 115 kW of power;[9] cooling and storage likely more than doubled this figure. A Data General SuperNova S/200 minicomputer served as the maintenance control unit (MCU), which was used to feed the Cray Operating System into the system at boot time, to monitor the CPU during use, and optionally as a front-end computer. Most, if not all, Cray-1As were delivered using the follow-on Data General Eclipse as the MCU.
The reliability of the CRAY-1A was very low by today's standards. At the European Centre for Medium-Range Weather Forecasts, which was one of the first customers, the mean time between hardware faults was reported to be 96 hours in 1979.[13] Seymour Cray deliberately made design decisions that sacrificed reliability for speed, but improved his later designs after being questioned on this matter. Similarily, the Cray Operating System (COS) was fairly rudimentary, hardly tested and updated weekly or even daily in the early days.
Cray-1S
The Cray-1S, announced in 1979, was an improved Cray-1 that supported a larger main memory of 1, 2 or 4 million words. The larger main memory was made possible through the use of 4,096 x 1-bit bipolar RAM ICs with a 25 ns access time.[14] The Data General minicomputers were optionally replaced with an in-house 16-bit design running at 80 MIPS. The I/O subsystem was separated from the main machine, connected to the main system via a 6 Mbit/s control channel and a 100 Mbit/s High Speed Data Channel. This separation made the 1S look like two "half Crays" separated by a few feet, which allowed the I/O system to be expanded as needed. Systems could be bought in a variety of configurations from the S/500 with no I/O and 0.5 million words of memory to the S/4400 with four I/O processors and 4 million words of memory.
Cray-1M
The Cray-1M, announced in 1982, replaced the Cray-1S.[15] It had a faster 12 ns cycle time and used less expensive MOS RAM in the main memory. The 1M was supplied in only three versions, the M/1200 with 1 million words in 8 banks, or the M/2200 and M/4200 with 2 or 4 million words in 16 banks. All of these machines included two, three or four I/O processors, and the system added an optional second High Speed Data Channel. Users could add a Solid-state Storage Device with 8 to 32 million words of MOS RAM.
Software
In 1978 the first standard software package for the Cray-1 was released, consisting of three main products:
- Cray Operating System (COS) (later machines would run UNICOS, Cray's UNIX flavor)
- Cray Assembly Language (CAL)
- Cray FORTRAN (CFT), the first automatically vectorizing Fortran compiler
The United States Department of Energy funded sites from Lawrence Livermore National Laboratory, Los Alamos Scientific Laboratory, Sandia National Laboratories and the National Science Foundation supercomputer centers (for high-energy physics) represented the second largest block with LLL's Cray Time Sharing System (CTSS). CTSS was written in a dynamic memory Fortran, first named LRLTRAN, which ran on CDC 7600s, renamed CVC (pronounced "Civic") when vectorization for the Cray-1 was added. Cray Research attempted to support these sites accordingly. These software choices had influences on later minisupercomputers, also known as "crayettes".
NCAR has its own operating system (NCAROS).
The National Security Agency developed its own operating system (Folklore) and language (IMP with ports of Cray Pascal and C and Fortran 90 later)[16]
Libraries started with Cray Research's own offerings and Netlib.
Other operating systems existed, but most languages tended to be Fortran or Fortran-based. Bell Laboratories, as proof of both portability concept and circuit design, moved the first C compiler to their Cray-1 (non-vectorizing). This act would later give CRI a six-month head start on the Cray-2 Unix port to ETA Systems' detriment, and Lucasfilm's first computer generated test film, The Adventures of André & Wally B..
Application software generally tends to be either classified (e.g. nuclear code, cryptanalytic code) or proprietary (e.g. petroleum reservoir modeling). This was because little software was shared between customers and university customers. The few exceptions were climatological and meteorological programs until the NSF responded to the Japanese Fifth Generation Computer Systems project and created its supercomputer centers. Even then, little code was shared.
Partly because Cray were interested in the publicity, they supported the development of Cray Blitz which won the fourth (1983) and fifth (1986) World Computer Chess Championship, as well as the 1983 and 1984 North American Computer Chess Championship. The program, Chess, that dominated in the 1970s ran on Control Data Corporation supercomputers.
Museums
Cray-1s are on display at the following locations:
- Bradbury Science Museum in Los Alamos, New Mexico
- Chippewa Falls Museum of Industry and Technology in Chippewa Falls, Wisconsin
- The Cray Inc. offices at Cray Plaza in St. Paul, Minnesota
- Computer History Museum in Mountain View, California[17]
- Computer Museum of America, Roswell, Georgia, US[18]
- DigiBarn Computer Museum[19]
- Deutsches Museum in Munich
- ETH Zurich - Eidgenössische Technische Hochschule Zürich, Switzerland
- Living Computers: Museum + Labs in Seattle, Washington[20]
- National Center for Atmospheric Research in Boulder, Colorado[21]
- National Air and Space Museum in Washington, D.C.[22]
- Musée Bolo in Lausanne, Switzerland
- The National Museum of Computing at Bletchley Park[23]
- Science Museum in London[24]
- Swedish National Museum of Science and Technology in Stockholm, Sweden[25]
- System Source Computer Museum in Hunt Valley, Maryland has a Cray-1, a Cray 1-s, and other Cray computers
- Computer Museum of America in Roswell, Georgia has four Cray-1s, plus other Cray computers
- Valladolid Science Museum in Spain.
Other images of the Cray-1
 Cray-1 with internals exposed at EPFL
Cray-1 with internals exposed at EPFL Logic boards
Logic boards Inside of the tower
Inside of the tower Cooling system
Cooling system Top of the casing
Top of the casing Close-up of logic boards
Close-up of logic boards Cray-1A power supply detail
Cray-1A power supply detail.jpg.webp) Cray-1 at Computer History Museum
Cray-1 at Computer History Museum Cray-1 at Computer History Museum
Cray-1 at Computer History Museum Cray-1 at Deutsches Museum
Cray-1 at Deutsches Museum The Cray-1 at the Science Museum, London
The Cray-1 at the Science Museum, London Cray-1 at the Computer Museum of America, Roswell, Georgia, US
Cray-1 at the Computer Museum of America, Roswell, Georgia, US.jpg.webp) Logic boards
Logic boards.jpg.webp) Some of the 50 miles of wiring
Some of the 50 miles of wiring Seymour Cray with his Cray-1
Seymour Cray with his Cray-1
References
- 1 2 3 4 5 6 7 Cray-1 Computer System Hardware Reference Manual 2240004, Rev C, Publication: 1977 November 4, Cray Research, Inc.
- ↑ C.J. Murray, "The ultimate team player," Archived October 28, 2008, at the Wayback Machine Design News, March 6, 1995.
- ↑ Swaine, Michael (October 5, 1981). "Tom Swift Meets the Big Boys: Small Firms Beware". InfoWorld. p. 45. Retrieved January 1, 2015.
- ↑ "SCD Supercomputer Gallery". NCAR. Archived from the original on June 7, 2015. Retrieved June 3, 2010.
- ↑ Budiansky, Stephen (2016). Code Warriors. New York: Alfred A. Knopf. pp. 298–300. ISBN 9780385352666.
- ↑ Rahul Garg (June 2, 2013). "Exploring the Floating Point Performance of Modern ARM Processors". Anandtech.
- ↑ "Apple A13 Bionic Specs".
- ↑ Fairchild Semiconductor, "Fairchild 11C01 ECL Dual 5-4 Input OR/NOR Gate," Fairchild ECL Databook, c. 1972.
- 1 2 Russell, Richard M. (January 1, 1978). "The CRAY-1 computer system". Communications of the ACM. 21 (1): 63–72. doi:10.1145/359327.359336. S2CID 28752186.
- ↑ "SCD Supercomputer Gallery: CRAY1-A". National Center for Atmospheric Research. Archived from the original on March 3, 2016. Retrieved January 30, 2016.
- 1 2 "The Cray-1 Computer System" (PDF). Cray Research Inc. Archived (PDF) from the original on October 9, 2022.
- ↑ "Company History - Cray". Archived from the original on July 12, 2014.
- ↑ Woods, Austin (2006). Medium-Range Weather Prediction – the European Approach. Springer. ISBN 978-0-387-26928-3.
- ↑ J.S. Kolodzey, "CRAY-1 Computer Technology," IEEE Trans. Components, Hybrids, and Manufacturing Technology, vol. 4, no. 3, 1981, pp. 181–186.
- ↑ "Cray Cuts Price". The New York Times. September 14, 1982.
- ↑ Frontiers of Supercomputing II. Retrieved February 8, 2014.
- ↑ Cray 1A. Computer History Museum. 1976. Retrieved May 15, 2012.
- ↑ "Computer Museum of America - THE collection of computer artifacts". Computer Museum of America.
- ↑ "Cray-1 Supercomputer (#38) and Memorabilia at the DigiBarn". DigiBarn Computer Museum. Retrieved May 15, 2012.
- ↑ "Two Cray Supercomputers Join Living Computers". Archived from the original on April 26, 2019. Retrieved April 26, 2019.
- ↑ "Cray 1". National Center for Atmospheric Research. Archived from the original on December 27, 2012. Retrieved May 15, 2012.
- ↑ "National Air and Space Museum". Archived from the original on January 21, 2012. Retrieved January 21, 2010.
This object is on display in the Beyond The Limits exhibition at the National Mall building.
- ↑ "A Cray 1 Arrives". The National Museum of Computing. Archived from the original on March 4, 2014. Retrieved February 27, 2014.
- ↑ "Cray 1A supercomputer, serial number 11, c 1979". NMSI. Retrieved May 15, 2012.
- ↑ TM44354 Dator Cray Research, Inc. Cray Research, Inc. 1976 SAAB Aerospace Archived January 6, 2011, at the Wayback Machine, p. 52, Datorföremål+på+TM.pdf. Retrieved 2012-05-15.
External links
- CRAY-1 Computer System Hardware Reference Manual, Publication No. 2240004 Rev.C 11/77 (first three chapters) – From DigiBarn / Ed Thelen
- CRAY-1 Computer System Hardware Reference Manual, Publication No. 2240004 Rev.C 11/77 (full, scanned, PDF)
- Collection of on-line Cray manuals & documentation @ Bitsavers
- Cray Channels Magazine @ The Centre for Computing History
- Cray Manuals & Documentation @ The Centre for Computing History
- Cray Users Group Publications @ The Centre for Computing History
- NCAR Supercomputer Gallery
- Verilog definition of Cray-1A CPU logic
Cray computers | ||
|---|---|---|
| Cray Research |  | |
| Cray Computer Corp. | ||
| Cray Research Superservers | ||
| Cray Inc. | ||